U-NET¶
Paper PDF : https://arxiv.org/pdf/1505.04597.pdf
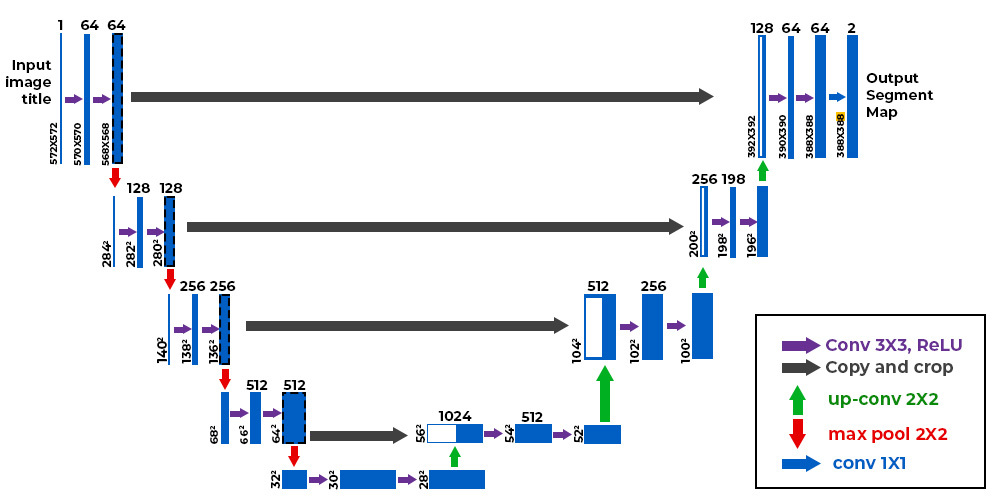
U-Net is an architecture developed by Olaf Ronneberger, Philipp Fischer, and Thomas Brox for Biomedical image segmentation. They won the ISBI (International Symposium on Biomedical Imaging) cell tracking challenge 2015 in New York.
U-Net Architecture¶
It is named as "U-Net" cause it has U-shape network architecture. U-Net architecture consists of three parts : contracting path or encode (left side), expansive path or decode (right side), and skip connection.
Contracting Path or Encoder¶
The Contracting Path or Encoder acts as a feature extractor. The Encoder consists of two convolutional layers with downsampling using a 3x3 filter size, ReLU activation, and a 2x2 max pooling operation. The Encoder step is repeated four times, with the number of features increasing by a factor of two at each step (64, 128, 256, 512). In this step, the output of the last convolutional layer in each Encoder cycle is transferred over the skip connection.
Skip Connections¶
Skip connections are used to retain spatial information because the Encoder reduces the spatial information from the input. Skip connections involve concatenating the feature maps from the Encoder to the output of the corresponding Transposed Convolutional layer. This process occurs within the same step of the architecture.
Bridge¶
Bridge in U-Net refers to the middle part of the architecture that connects the encoder and de coder. It consists of two 3x3 convolutions with 1024 number of filters, where each convolution is followed by a ReLU activation function.
Expansive Path or Decoder¶
Expansive path or decoder is responsible for upsampling the feature maps and generating the final output. Decoder uses transposed convolutional layers (also known as deconvolution layers). Decoder consist of 2x2 transposed convolutional and concatenate with the feature maps on skip connections. After that, two 3x3 convolutions are used, where each convolution is followed by a ReLU activation function. The output of the last decoder passes through a 1x1 convolution with sigmoid activation. The sigmoid activation function gives the segmentation mask representing the pixel-wise classification.