Kalman Filter¶
The Kalman Filter is used for prediction and estimation of the state of a system. The Kalman filter requires two models: the state model and the observation model.
- State Model : A model that represents changes in the state of the system with respect to time.
- Observation Model : An equation/model that represents data measured, usually by sensors, providing external data about the robot and linking it to the system's state.
Multivariate Kalman Filter¶
The system state is represented as:
Multivariate Kalman Filter produces outputs in the form of multivariate random variables and a covariance matrix, which is a square matrix representing the uncertainty of the states. The Covariance matrix in the Kalman Filter includes:
- \(P_{n,n}\): covariance matrix for estimation
- \(P_{n+1,n}\): covariance matrix for prediction
- \(R_n\): covariance matrix representing measurement uncertainty
- \(Q\): covariance matrix for process noise
Covariance¶
Covariance measures the correlation between two or more random variables.
Covariance between population \(X\) and \(Y\), with \(N\) data points:
For a sample:
Covariance Matrix¶
The covariance matrix is a square matrix representing the covariance between each element of each state.
If \(x\) and \(y\) are uncorrelated, the off-diagonal elements of the matrix \(\Sigma\) are zero.
For a state \(x\) of dimension \(1 \times k\):
Proof :
Note :
\(E(v)\) is the expectation or mean of the random variable.
Covariance Matrix Properties¶
Multivariate Gaussian Distribution¶
State Equation¶
State Equation Used to make predictions based on existing estimates.
\(\hat{x}_{n+1,n} = F\hat{x}_{n,n} + G\hat{u}_{n,n} +w_n\)
- \(\hat{x}_{n+1,n}\) : predicted state at \(n+1\)
- \(\hat{x}_{n,n}\) : predicted state at \(n\)
- \(u_n\) : control input measured into the system
- \(w_n\) : noise, unmeasured input (called process noise)
- \(F\) : transition matrix
- \(G\) : control matrix (mapping the effect of \(u_n\) to the state variables)
Covariance Equation¶
Measures the uncertainty of predictions made by the State Equation
\(P_{n+1,n} = FP_{n,n}F^T + Q\)
Proof :
Using \(COV(x) = E((x_{1:k}-\mu_{x_{i:k}})(x_{1:k}-\mu_{x_{i:k}})^T)\), then \(P_{n,n} = E((\hat{x}_{n,n}-\mu_{\hat{x}_{n,n}})(\hat{x}_{n,n}-\mu_{\hat{x}_{n,n}})^T)\)
From the state equation, \(P_{n+1,n}\) is derived as:
Thus,
Observation Model¶
\(z_n = Hx_n+v_n\)
- \(z_n\) : observation vector
- \(H\) : observation matrix
- \(x_n\) : true state
- \(v_n\) : random noise (called observation noise)
For example, in the case of an ultrasonic distance sensor, where the system state is the distance \(x_n\) and the sensor output is the measured ToF \(z_n\)::
\(z_n = [\frac{2}{c}]x_n + v_n\)
Where \(c\) is the speed of sound.
Observation Uncertainty¶
\(R_n = E(v_nv_n^T)\)
- \(R_n\): covariance matrix for observation
- \(v_n\): observation error
Process Uncertainty¶
\(Q_n = E(w_nw_n^T)\)
- \(Q_n\): covariance matrix for process noise
- \(w_n\): process noise
Summary¶
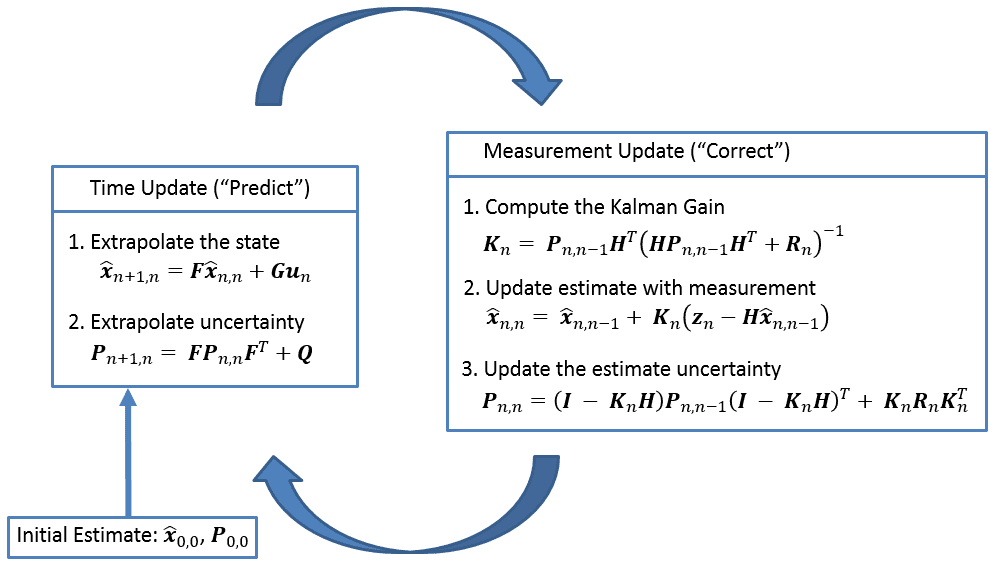
Kalman Gain¶
Kalman Gain determines the weighting for the measurement model. It defines the influence of the measurement model on state estimation:
- If \(error_{estimate} > error_{measurement}\), then \(KG \rightarrow 1\)
- If \(error_{estimate} < error_{measurement}\), then \(KG \rightarrow 0\)
Error on Estimation¶
- If \(KG\rightarrow1\), the error on the estimation is large, resulting in a smaller \(E_{estimate}\).
- If \(KG\rightarrow0\), the error on the estimation is small, maintaining the estimation error from time \(t-1\). Thus,
- \(E_{estimate_t} < E_{estimate_{t-1}}\)
Note: As the estimation variance decreases, it approaches the true value.